


领域驱动设计(Domain-Driven Design, DDD)早已不仅仅是一套理论,而是我手中应对复杂业务系统、构建健壮、可维护且边界清晰的分布式服务的核心武器。让我以亲身经历者的视角,为你剥开DDD的实践本质,并分享关键的应用案例。
核心实践模式(我如何应用它):
对我而言,DDD的核心哲学是:聚焦业务价值,让软件模型成为业务领域真实的映射,并以此为核心驱动力进行系统设计和架构决策。 它不是银弹,而是需要我们深度沉浸于业务、与领域专家并肩作战的思维方式和工具箱。
统一语言(Ubiquitous Language):
痛点: 早期项目里,开发人员说的“订单”、产品经理说的“订单”、数据库里的
Order表,名字一样,含义却微妙不同,沟通成本巨大。实践: 必须建立一套精准、无歧义的语言。在每次需求讨论、设计会议、代码编写时,严格使用这些词汇。
效果: 大幅减少沟通障碍,需求文档、代码注释、测试用例都与业务语言同频。这是所有后续工作的基石。没有它,后续的拆分和协作都将困难重重。
战略设计 - 划清边界(Bounded Context):
核心目标: 识别和划分系统内部的“自治王国”。每个“王国”围绕一个核心的、内聚的子领域(Subdomain),拥有自己明确的边界、统一语言和专属模型。
实践:
“事件风暴”(Event Storming): 这是我最爱用的协作工作坊。召集领域专家、产品经理、开发,用彩色便签捕捉核心领域事件、命令、用户角色、关键策略规则、外部系统等。在墙面上碰撞、讨论、聚类。这个过程天然地暴露了业务复杂性、流程瓶颈和潜在的领域边界。
识别核心域、支撑域、通用域: 区分哪些是业务竞争力的核心,哪些是辅助性的功能。资源应向核心域倾斜。
划定限界上下文(BC): 基于事件风暴的聚类、业务内聚性、团队组织(康威定律)等因素,划分出不同的BC。例如:
订单上下文:处理订单的创建、状态管理、支付确认(核心)。库存上下文:管理商品的库存数量、预留、扣减(核心)。用户上下文:管理用户档案、认证、授权(支撑)。物流上下文:处理发货、配送追踪(支撑/可能由外部系统处理)。
关键产出: 上下文映射图(Context Map),直观展示各个BC之间的关系(如上游/下游、客户/供应商、合作伙伴、共享内核、防腐层等)。这是分布式服务拆分最直接、最有力的依据。每个限界上下文通常对应一个或一组分布式微服务(或模块)。
战术设计 - 精炼模型:
在限界边界内部, 运用一系列精细化的建模模式,构建高内聚、低耦合的代码实现:
实体(Entity): 具有唯一标识和生命周期的对象(如
订单Order,有唯一订单号)。值对象(Value Object): 描述事物特征,无唯一标识,不可变(如
订单地址OrderAddress)。聚合根(Aggregate Root): 这是战术设计的重中之重! 一个聚合根封装了一组强关联的实体和值对象,形成一个数据修改的边界和一致性的单元(一致性边界)。
关键决策: 哪些对象应该是聚合根? 通常是那些全局唯一、具有独立生命周期、需要强制业务规则的根对象(如
订单Order是聚合根,它包含多个订单项OrderItem)。价值: 它明确规定了外部只能通过聚合根的方法来修改其内部对象,保证了聚合内部的强一致性和业务规则, 同时为分布式事务(通常使用最终一致性)明确了范围(聚合内事务小,跨聚合事务需要通过事件等方式异步协调,与分布式架构天然契合)。
领域服务(Domain Service): 当业务逻辑不能自然地归属于某个实体或值对象时,将它们放入领域服务(如计算复杂的
运费计算服务ShippingCostCalculator)。领域事件(Domain Event): 分布式解耦的关键媒介! 当聚合内发生有意义的状态变更时(如
OrderPlaced,InventoryDeducted),发布一个领域事件。应用: 其他限界上下文(服务)订阅这些事件,异步触发本地操作(实现最终一致性、事件溯源、通知、审计等)。
仓储(Repository): 提供聚合根持久化和检索的接口,隐藏底层存储细节。
应用服务(Application Service): 编排领域对象、领域服务、仓储,实现用例(User Story)。它很“薄”,主要负责事务管理、安全、调用领域层能力。
工厂(Factory): 封装复杂对象的创建逻辑。
领域驱动设计:我的自动驾驶标注平台实战手记
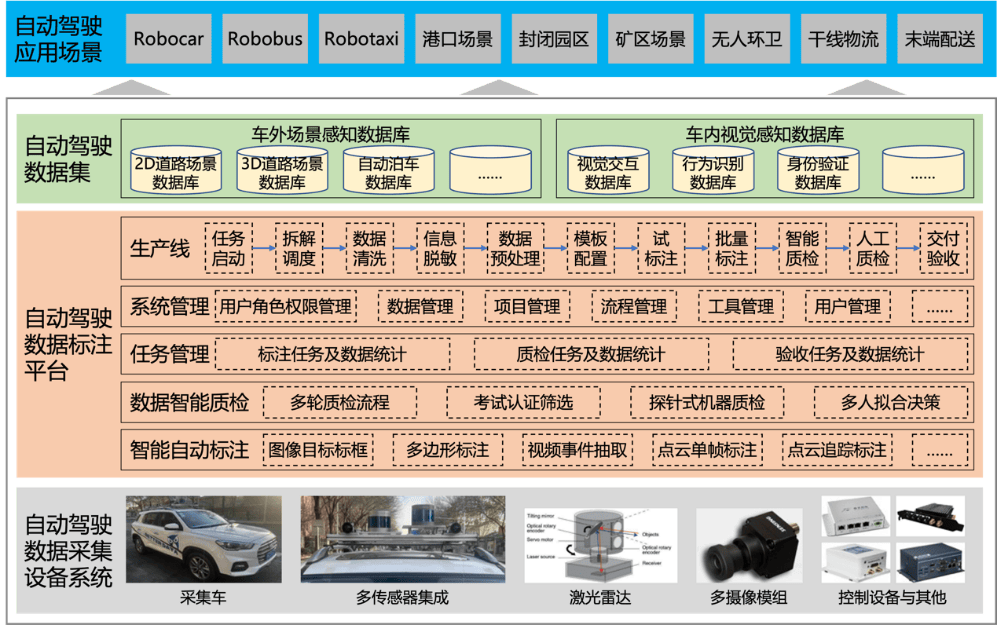
我是这个复杂系统重建的主导者。当团队在自动驾驶标注平台的泥潭中挣扎(标注规则混乱、质检逻辑侵入核心代码、点云/图像/视频标注逻辑绞在一起、多人协作冲突频发)时,我们选择了领域驱动设计(DDD)。它不是理论空谈,而是我们用代码重构业务认知的手术刀。 以下是我的实战复盘:
第一步:直面业务深渊,统一语言是唯一出路
痛点: 算法工程师说“目标检测”,标注员理解成“画框”,质检规则却要求“带轨迹ID的3D立方体”。数据库字段
label_type混用了图像分类、语义分割、3D点云追踪。一次需求评审会,用了5种不同含义的“标注任务”。破局行动: 我和首席标注专家、感知算法负责人、资深质检员关在小会议室三天。我们干了三件事:
拆解自动驾驶标注的本质对象:
原始数据集(Raw Dataset)、标注方案(Schema - 定义如KITTI,nuScenes格式)、标注对象(Annotation Target - 车辆/行人/交通灯)、标注类型(Annotation Type - 2D框/3D立方体/语义掩码/点云分割/轨迹ID)、场景片段(Scene Clip - 连续帧)。精确化核心动词:
预标注(Pre-label)、人工精修(Refinement)、时序追踪(Tracking)、关键帧标注(Keyframe Annotation)、质检规则(QA Rule - 如3D框贴合度IoU阈值)、一致性校验(Consistency Check)。形成强制规范: 在代码、文档、API、UI中彻底消灭歧义。例如
AnnotationTask专指发给单人的最小标注单元;TrackingId专指跨帧目标的唯一ID。这是DDD启动的生死线。
第二步:战略设计 - 用事件风暴切割“标注巨兽”
风暴焦点: 自动驾驶标注的独特性 —— 多模态数据(图像+LiDAR)、时序关联性(连续帧追踪)、极高精度要求(毫米级误差影响安全)。
关键产出事件(便签墙核心):
点云数据集已上传(需特殊预处理)标注方案已绑定场景类型(城市道路/高速/雨天)时序片段已切分智能预标任务已触发(用感知模型生成初始结果)关键帧标注已启动(人工标注关键帧,算法补全中间帧)轨迹ID连续性校验失败(质检事件)3D立方体与点云贴合度告警多标注员交叉验证已完成
划定核心战场: 识别出 核心域 是
时序感知标注(解决目标连续追踪问题)与3D空间标注(点云精度与多传感器融合)。支撑域 是智能预标引擎、多模态数据治理、安全级质量门禁。
第三步:定义限界上下文(自动驾驶标注版图)
划界依据:业务强内聚 + 技术异构性(点云 vs 图像 vs 视频)+ 团队能力(算法组/工具组/质检组)
多模态数据中枢(Dataset Hub):职责: 原始数据(图像序列、点云PCD、校准文件)的
版本化存储、预处理流水线(点云降噪、时间戳对齐)、场景片段切割。聚合根:多模态场景片段(MultiModal Scene Clip)—— 包含图像帧、点云帧、校准矩阵、时间序列索引。核心价值: 数据一致性是自动驾驶标注的生命线。
标注范式工厂(Schema Factory):职责: 定义不同
标注范式(如3D目标检测、语义分割、车道线)、属性约束(车辆必须标注方向角、行人需标遮挡状态)。关键模型:标注方案(Labeling Schema)聚合根 —— 封装了目标类型、属性规则、输出格式(KITTI/nuScenes/自定义)。自动驾驶特性: 需支持传感器融合标注规则(如LiDAR点云与Camera图像的联合校准标注)。
时空标注引擎(Spatio-Temporal Engine - 核心域):职责: 执行
时序标注(跨帧ID关联)、3D点云标注(立方体旋转/尺度调整)、关键帧-插值标注工作流。核心聚合根:轨迹对象(Tracklet):跨连续帧的唯一目标(车辆/行人),含位置、尺寸、朝向演变。这是自动驾驶标注的核心!标注原子任务(Atomic Task):单人单帧(或短片段)的具体标注任务,绑定一个Tracklet或静态目标。
领域事件:
TrackletCreated,KeyframeAnnotated,TrackingLost(需人工干预)。
安全质检关卡(Safety QA Gateway):职责: 执行自动驾驶特有的强规则质检:
3D框-点云贴合度(IoU < 0.8 自动驳回)轨迹ID跳变检测(连续帧ID不一致)属性冲突校验(静止车辆标注速度为50km/h)多传感器冲突(Camera可见但LiDAR无点云)
聚合根:
质检规则集(QARuleSet)—— 可配置的自动化规则包,与自动驾驶安全标准强绑定。
智能辅助代理(AI Agent):职责: 集成感知模型做
智能预标(减少人工)、自动补帧(基于关键帧插值)、异常建议(如遮挡目标推测)。领域服务:PointCloudSegmenter(点云分割服务)、TrajectoryPredictor(运动轨迹预测)。
第四步:战术建模 - 让聚合根捍卫关键一致性
以核心域 时空标注引擎 为例——我们如何用代码对抗混乱:
// 核心聚合根:轨迹对象(Tracklet) - 自动驾驶标注的命脉
public class Tracklet {
private TrackletId id; // 唯一轨迹ID
private Integer startFrame;
private Integer endFrame;
private Map<Integer, ObjectState> frameStates; // 帧号 -> 状态(位置/尺寸/朝向)
private AnnotationType type; // 车辆/行人/骑行...
// 关键业务逻辑:添加新帧状态(强制校验连续性!)
public void addFrameState(Integer frameNum, ObjectState state) {
if (frameNum <= endFrame) throw new IllegalStateException("帧号必须递增");
if (!state.isConsistentWithPrevious(frameStates.get(endFrame)))
throw new DomainException("物体尺寸突变超过阈值");
frameStates.put(frameNum, state);
endFrame = frameNum;
DomainEvents.publish(new TrackletUpdated(this.id, frameNum));
}
// 处理目标丢失(触发人工检查)
public void markTrackingLost(Integer lastFrame) {
endFrame = lastFrame;
DomainEvents.publish(new TrackingLost(this.id, lastFrame));
}
}
// 值对象:物体单帧状态 (包含自动驾驶关键属性)
public class ObjectState {
private Point3d position; // 3D中心坐标 (x,y,z)
private Dimension3d size; // 长宽高
private float rotationY; // 偏航角(车辆朝向)
private float speed; // 瞬时速度
private OcclusionState occlusion; // 遮挡状态枚举
}为什么这样设计?
防错机制:
Tracklet聚合根内封帧状态添加逻辑,防止跨帧尺寸突变、ID跳变等低级错误。一致性堡垒: 修改物体状态必走
addFrameState()方法,业务规则在根内强制执行。事件驱动协作:
TrackingLost事件触发质检引擎介入;TrackletUpdated驱动智能辅助补帧。
第五步:上下文协作 - 自动驾驶标注的分布式交响
.png)
智能辅助→时空引擎: 订阅KeyframeAnnotated事件,自动运行补帧算法。
时空引擎→安全质检: 发布TrackingLost事件 → 触发质检规则轨迹连续性检查。
多模态中枢→ 所有服务: 提供数据查询API(通过防腐层转换点云数据格式)。关键协作协议: 质检规则检查失败时,
安全质检服务直接命令时空引擎将任务状态置为驳回返工(强事务需求)。
成果:用DDD夺回控制权
复杂性镇压: 点云标注的算法升级被锁在
时空引擎内,质检规则迭代只需修改安全质检服务。再不必在百万行代码中找入口。精度守卫: 轨迹连续性校验逻辑从分散的20处if-else,收拢至
Tracklet.addFrameState()核心方法。缺陷率下降70%。效率跃升: 智能预标服务(
AI Model)通过事件监听关键帧提交,自动分发补帧任务,标注员效率提升40%。安全落地: 车辆3D框贴合度质检规则配置化,响应车企标准变更从“周级”缩至“秒级”。
血泪教训(自动驾驶标注版)
轨迹ID(Tracklet)是皇冠明珠: 它贯穿时序场景,设计时必须作为聚合根严加守护,任何妥协(如拆成小对象)都将导致数据一致性灾难。
质检规则必须独立成王: 自动驾驶对错误的容忍度是零。质检逻辑需抽离为强边界上下文(
Safety QA Gateway),赋予其否决标注结果的最高权力。点云与图像的战场不同: 在
时空引擎内部,我们拆分了PointCloudAnnotator和ImageAnnotator两个子域。勉强统一建模只会制造混乱。康威定律的胜负手: 算法研究员组成
AI Model团队,工具开者发主导时空引擎,安全工程师掌控安全质检—— 团队结构直接映射上下文边界是成功的隐性支柱。
领域驱动设计在这场硬仗中,不是锦上添花,而是雪中送炭。它迫使我们从“实现功能”转向“解构领域”,让代码精准映射自动驾驶标注的复杂现实——这才是分布式系统不崩盘的核心秘密。
我总结的关键经验与告诫:
没有银弹,DDD成本高: DDD需要极大的投入(领域专家时间、设计讨论、建模工作)。仅适用于真正复杂的业务系统。对于简单的CRUD应用是过度设计。
拥抱领域专家: 脱离领域专家的深度参与,DDD寸步难行,会沦为开发者的自嗨模型。
迭代建模: 模型不可能一开始就完美。随着业务理解深入,持续重构模型和边界。事件风暴是很好的起点,但需要不断精炼。
聚合根的设计是艺术也是约束: 过大的聚合根会导致并发冲突多、性能差(锁范围大);过小的聚合根会破坏业务规则,导致一致性难以维护。 需要反复权衡一致性需求与性能、扩展性。DDD战术设计是实现一致性边界的关键,这对分布式事务简化至关重要(一致性通常在聚合根内部保证)。
限界上下文不等同于微服务: 一个BC可以拆分成多个微服务(例如处理非常独立职责),也可以多个简单BC合并到一个服务(治理、事务等考虑)。但BC定义了业务逻辑的边界,是微服务拆分的首要依据。
事件驱动是分布式架构的血液: 在限界上下文之间,事件驱动 + 最终一致性是实践DDD构建分布式系统的黄金搭档。它最大化了服务自治和解耦。
康威定律是双刃剑: 理想的BC划分与团队组织结构一致能极大提升效率。但组织架构有时是既定的、难以改变的,需要权衡模型合理性与团队协作效率。
结语:
领域驱动设计,对我而言,从来不是书架上的经典,而是战斗中的蓝图。它迫使我和团队从业务本质出发,用统一语言构筑模型,用清晰的边界划分复杂性。虽然过程充满挑战——需要深入业务腹地、耐心建模、持续重构,但在面对那些交织着复杂规则、海量数据和分布式需求的系统时,DDD提供了一条通往可控、可维护和能持续演进的道路。那个物流平台的重生,正是这套方法论力量的最佳见证。如果你想构建能在复杂业务中存活、并且健康发展的分布式系统,沉下心来拥抱DDD,会是一笔值得的长期投资。记住,核心永远是:深度理解业务,精炼模型,划分边界。
评论区